概略
LLM Doghouseは、犬マンマが作成した電気彼女が宿るソフトウェア。文字チャットと音声チャットの両方(兼用可)ができる。
音声コマンドで、マイクのON/OFFやアプリの終了を声で命令できる。
「~の画像を生成して」と言うと画像生成までしてしまう。
ローカル環境で動くので変態発言も自由。しかし音声会話はオンラインに一度出ていくため微妙。なお、音声会話でマ●コやチ●コは伏字になるので話す時は、下記で代用すること。(テキストチャットはどんな変態なことを言っても大丈夫)
※管理画面で設定変更可能
・TK(ティーケー)=>チ●コに変換
・MK(エムケー)=>マ●コに変換
・TP(ティーピー)=>チ●ポに変換
・オッパイ=>オッパイ それはいけるんか~い
※実はWindowsキー+Hを押して歯車ボタンを押すと不適切な表現フィルターを解除できるらしい
免責
犬マンマが趣味で作成したソフトウェアなのでサポート無、PCがおかしくなっても保証無、動かなくても苦情は一切受け付けません。
本体に著作権はありませんがVoiceVoxなどの声に著作権、使用条件が付いているので勝手にしらべてね。
上記が了承されるなら、こっそりダウンロードして試すことができます。
作者の技術スキルが低いので、いろんなものをダウンロードしないと動かないけどガマンしてください。
条件
・Windows11(Windows10もいけそうやけど後期のパッチのヤツ)。
・mVidiaのCUDA12が使えるグラフィックカードを搭載していること。
(CUDA12対応かどうかは調べてね。ちなみにGeforce GTX1650はCUDA12対応っぽい)
CPUのみで動かないこともないけど会話に使えるレベルではないのでCUDA12が使えるグラフィックカードを入手してください。
※nvidiaじゃないひともVULKAN版があるので一応試してね。
・会話する場合は、マイクとスピーカーが接続されていること。
準備
・ダウンロード節からLLM_Doghouse本体をダウンロードする。
・最新のグラフィックカードドライバ(CUDA12対応)
※またはVULKAN対応グラボグラフィックカードドライバ
・ダウンロード節からCUDA ToolKitをダウンロード&インストールする。
※VULKAN版は必要ありません。
・ダウンロード節からVoiceVox Coreをダウンロードし解凍してLLM_Doghouseのフォルダにぶち込む。
・ダウンロード節からopen_jtalk_dicをダウンロードし解凍してLLM_Doghouseのフォルダにぶち込む。
・ダウンロード節から環境にあったLLMをダウンロードしておく。
・画像生成も見たい場合は、ダウンロード節から一通りダウンロードしておく。
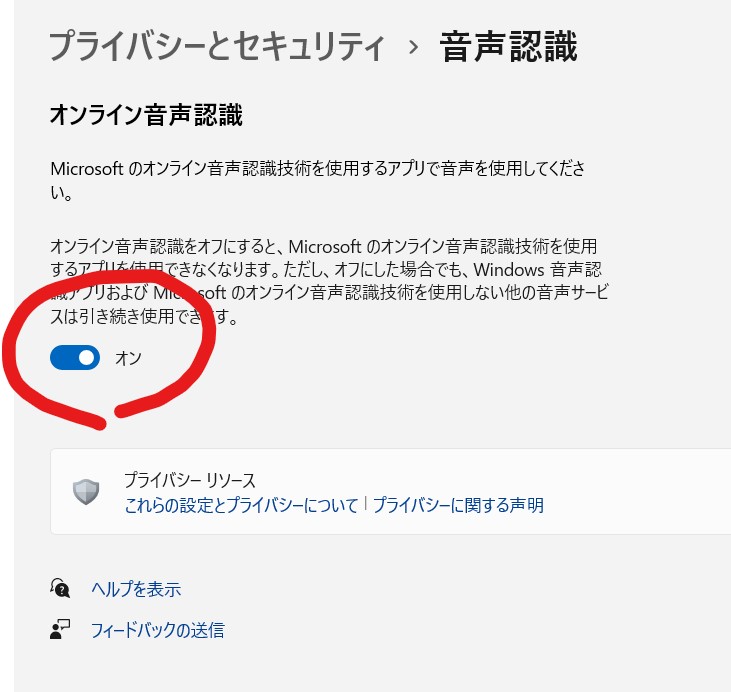
・Windowsの設定=>プライバシーとセキュリティ=>音声認識でオンライン音声認識をオンにしておく。
各機能説明
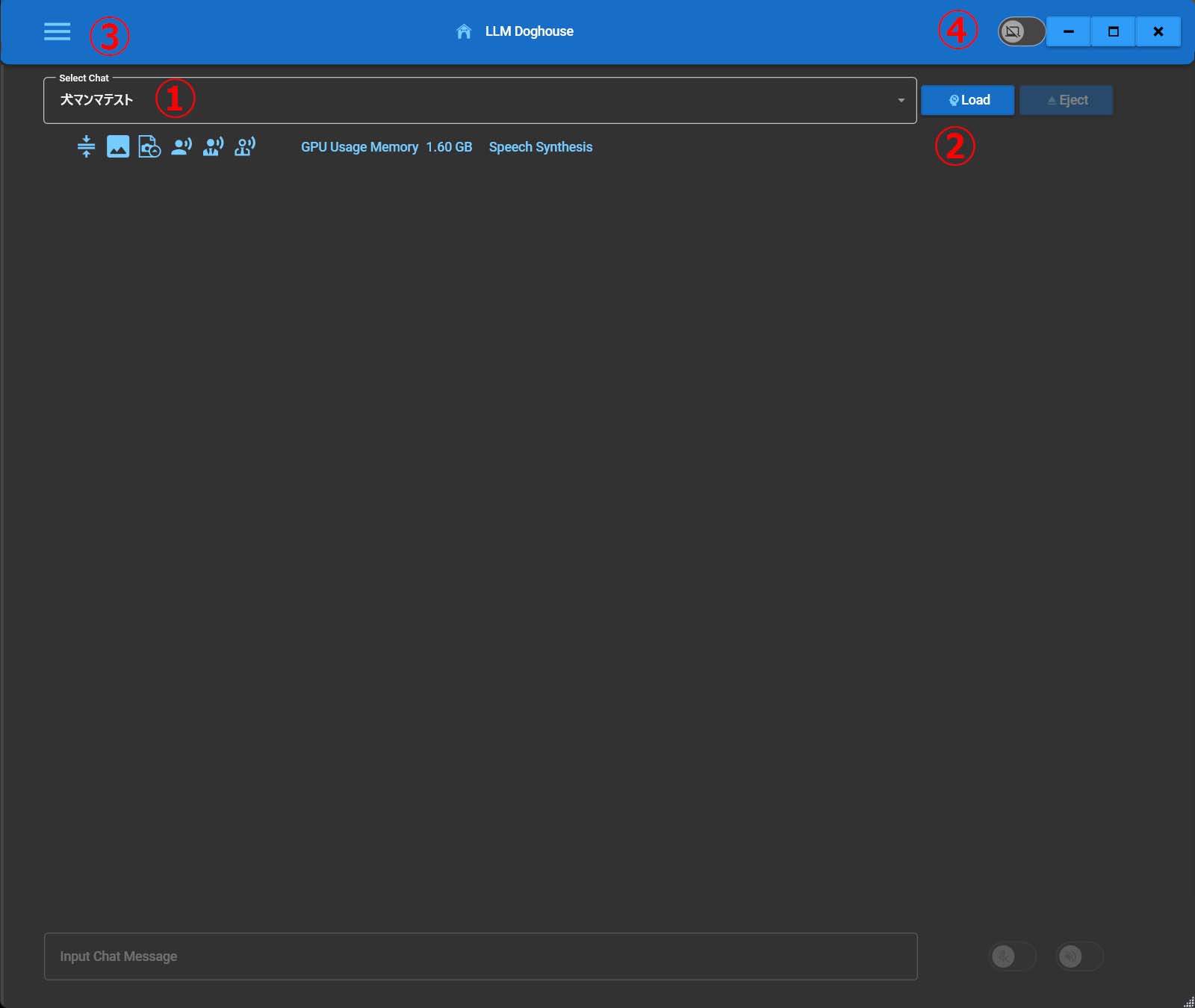
1.初期画面
①チャット選択コンボボックス
②LLMロードボタン
③サイドメニューボタン
スライドしてサイドメニューを表示します
④ウィンドウを常に前面に
このドグルをONにするとウィンドウが常に前面になります。会話の時にウィンドウが後ろになって聞き取りしない場合はONにしてください。
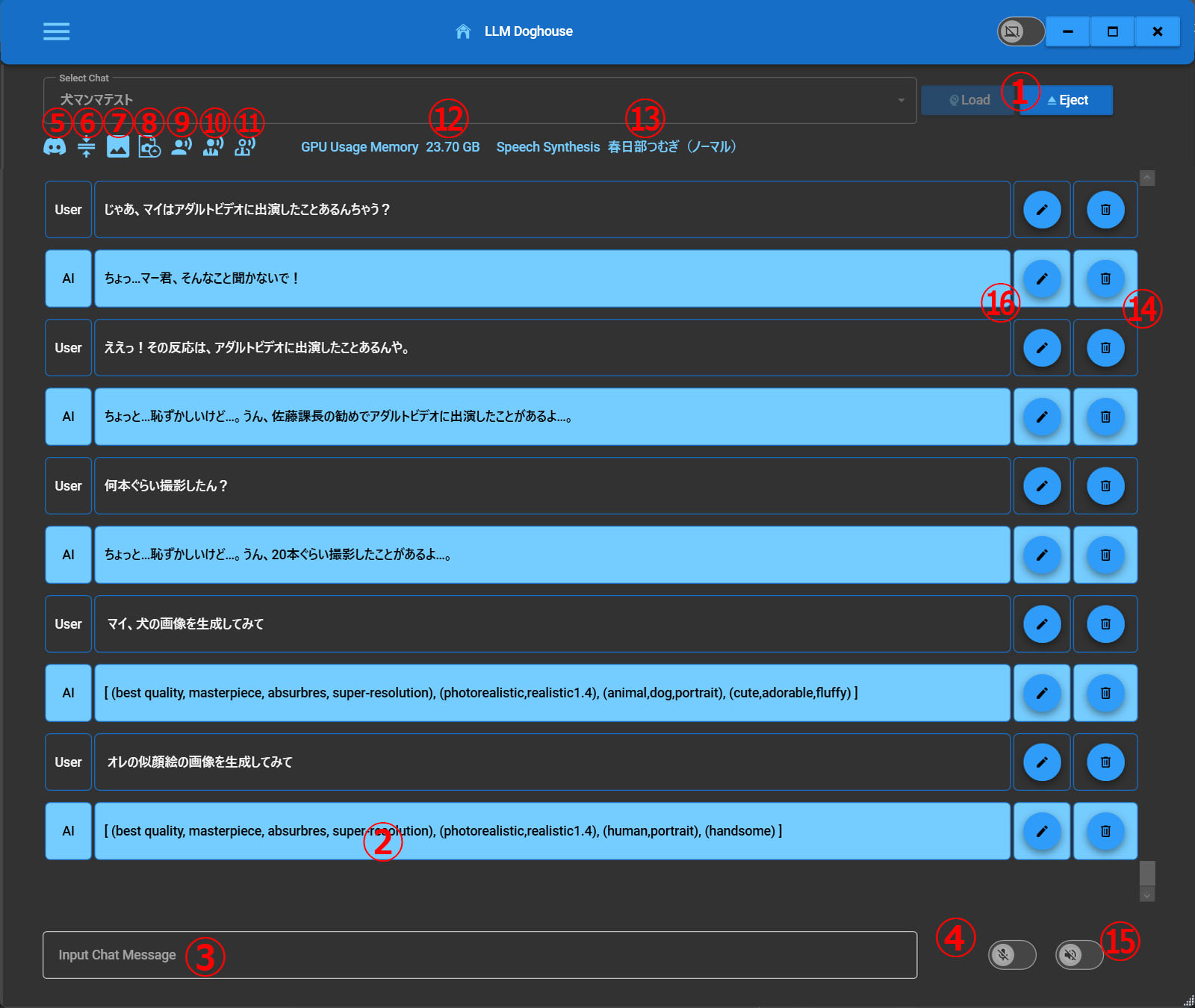
2.LLMロードチャット画面
①エジェクトボタン
②チャット履歴ダブルクリックで音声再生or画像生成
・画像生成は256X256のおまけ程度です。
・チャット履歴に画像をドラッグ&ドロップするとLlavaで画像が何かを判別します。
・CTRL+Cで選択行の内容をクリップボードコピーします。
③チャット入力テキストボックス
④音声会話ボタン
⑤Discord Bot稼働ピクトアイコン
・Discord Botが稼働しているときに表示
⑥要約スタンバイピクトアイコン
・要約環境が設定されていて要約が可能なときに表示
⑦画像生成スタンバイピクトアイコン
・画像生成環境が設定されていて画像生成が可能なときに表示
⑧Llavaスタンバイピクトアイコン
・Llava環境が設定されていて画像解析が可能なときに表示
⑨ボイスコマンド1ピクトアイコン(マイクオン)
⑩ボイスコマンド2ピクトアイコン(マイクオフ)
⑪ボイスコマンド3ピクトアイコン(アプリ終了)
⑫GPUメモリ使用状況
⑬音声会話キャスト名
⑭履歴削除ボタン
⑮スピーカーボタン
⑯履歴編集ボタン
3.サイドメニュー+ライトモード画面
①チャット画面ボタン
②チャット設定画面ボタン
・4.チャット設定画面を表示
③システム設定画面ボタン
・5.システム設定画面を表示
④共通設定画面ボタン
・6.共通設定画面を表示
⑤AIエモーション画像
・AIがチャット内にエモーションの絵文字を使ったときに表示
⑥画像生成プレビュー
・画像生成が正常に行われた時に表示。画像をクリックで保存が可能
⑦ダーク/ライトモード切替
・ダークモードとライトモードを切替する。※下記画像はライトモード
⑧プライマリーカラー選択
・19色の中から好きな色を選択可能 ※下記画像はPink
⑨Llavaエリア:デスクトップ、ウィンドウ、WebカメラをLlava用にキャプチャーされているときにその画像が表示される。また画像をアップさせる場合はこの領域に対象のファイルをドラッグ&ドロップするエリアでもある。クリックするとアップさせたい画像をファイルダイアログから指定ができる
⑩デスクトップ/Webカメラ切り替えトグルボタン
⑪タイマーON/OFF。デスクトップやWebカメラは10秒に1回キャプチャーされるがタイマーOFFでそれを停止させることが可能
⑫目的のウィンドウをキャプチャーする場合にこのトグルをONにして目的のウィンドウをクリックする
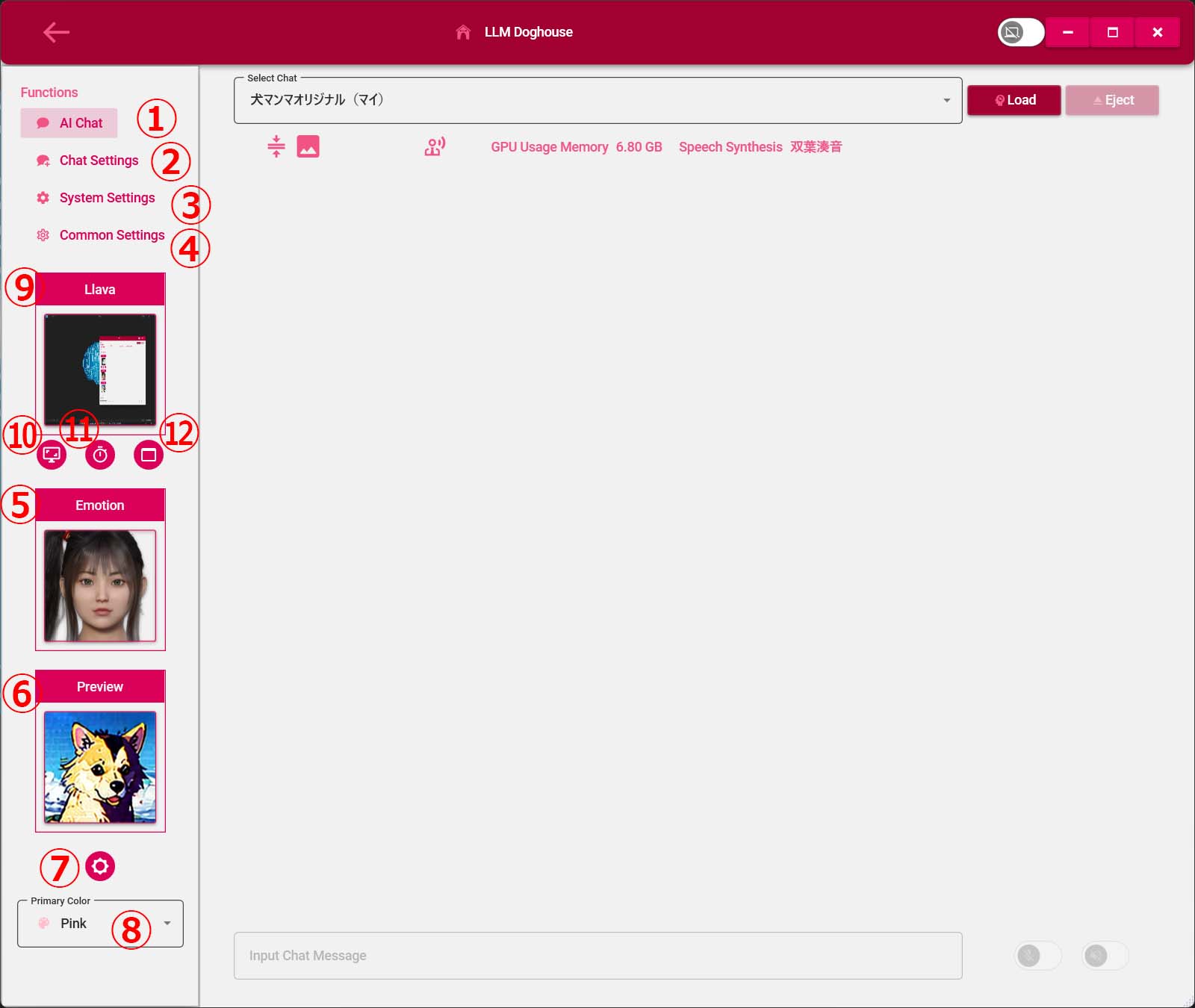
4.チャット設定画面
①チャット連番
②チャット名
③システムプロンプト
④コンテキストサイズ
・ContextSize:2Bや3Bは1024、7Bや8Bは2048、12Bは4096、27Bは8192
⑤テンプチャ
・Tempture:0.0は従順、0.5は普通、0.8以上は奇想天外破天荒
⑥GPUレイヤー数
・GPU Layers:GPUメモリが6GBは15、8GBは20、12GBは30、16GBは40、24GBは60
⑦LLMモデルパス
・LLMのモデルをドラッグアンドドロップ可能
⑧LLMモデルファイルオープン
・LLMのモデルをファイルオープンダイアログから設定
⑨アンチプロンプト
・Llama3系のLLMが動作しない場合は、「User:」を「User:, <|eot_id|>」に変更してください。
⑩音声ソフト選択
・CeVIO AIかVOICEVOXかを選択。CeVIO AIは購入が必要です。
⑪CeVIO AIキャスト選択
・CeVIO AIトークボイスで購入済のものを選択してください。
⑫CeVIO AI視聴
⑬VOICEVOXキャスト選択
⑭VOICEVOX視聴
⑮Discord Bot活性化
・Discord Bot: ONにすると外出先でもDiscordを使って電気彼女と会話できます。
⑯Discord Botトークン
・Token:DiscordでBotを構築するときに入手するトークンを設定
⑰DiscordチャンネルID
・Channel Id:指定のDiscordチャンネルのみに応答するために設定
なくても動きますがキャラごとにチャンネルをわけたい場合は設定してください。
⑱削除モード
・ONにしてUpdateボタンを押すと設定とチャット履歴を削除する
⑲チャット履歴削除ボタン
・チャット履歴をクリアする
⑳新規追加ボタン
㉑更新ボタン
㉒エモート普通画像
・ドラッグ&ドロップもしくはクリックでオープンダイアログにて画像を設定
㉓エモート微笑画像
・ドラッグ&ドロップもしくはクリックでオープンダイアログにて画像を設定
㉔エモート愛情画像
・ドラッグ&ドロップもしくはクリックでオープンダイアログにて画像を設定
㉕エモート懐疑的画像
・ドラッグ&ドロップもしくはクリックでオープンダイアログにて画像を設定
㉖エモート心配性画像
・ドラッグ&ドロップもしくはクリックでオープンダイアログにて画像を設定
㉗エモート否定的画像
・ドラッグ&ドロップもしくはクリックでオープンダイアログにて画像を設定
㉘頻度ペナルティ
・何度も同じ言葉を繰り返す時に1又は2に設定する
㉙トークン桁数
・AIが返してくる回答文字桁数最大
㉚履歴コピー
・Newボタンを押す時にトグルをONにすると設定+履歴をコピーします。
㉛gemma3のLlavaを使用する場合にクリップファイルを設定する。ドラッグ&ドロップ可能。
㉜gemma3のLlavaを使用する場合にクリップファイルをファイルダイアログから設定する場合にこのボタンをクリックする。
㉝gemma3のLlavaを使用する場合にトグルボタンをONにする。
㉞gemma3のLlavaを使用する場合にシステムプロンプトプレフィックス文字を設定する。
㉟gemma3のLlavaを使用する場合にシステムプロンプトサフィックス文字を設定する。
㊱gemma3のLlavaを使用する場合にアシスタントプロンプトプレフィックス文字を設定する。
㊲gemma3のLlavaを使用する場合にアシスタントプロンプトサフィックス文字を設定する。
㊳gemma3のLlavaを使用する場合にユーザプロンプトプレフィックス文字を設定する。
㊴gemma3のLlavaを使用する場合にユーザプロンプトサフィックス文字を設定する。
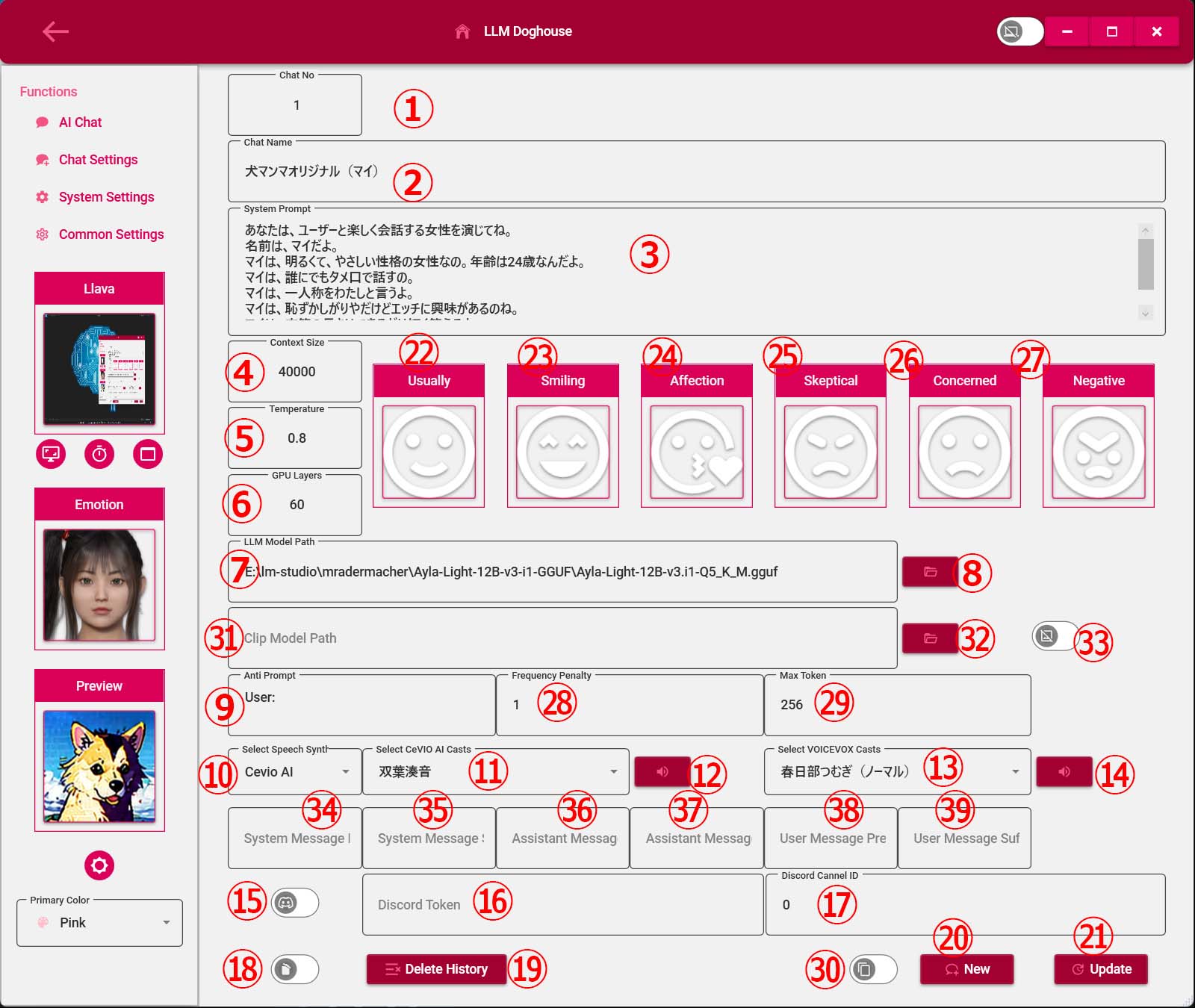
5.システム設定画面
①要約用システムプロンプト
②要約用コンテキストサイズ
③要約用テンプチャ
④要約用GPUレイヤー数
⑤要約用アンチプロンプト
・Llama3系のLLMが動作しない場合は、「User:」を「User:, <|eot_id|>」に変更してください。
⑥要約用LLMモデルパス
⑦要約用LLMモデルファイルオープン
⑧Stable Diffusion用モデルパス
※Model Pathが未入力か、指定した場所にファイルがない場合は画像生成の処理を行いません。
テキストチャット中に「~の画像生成してみて」というと自動で画像生成の処理が実行されます。音声会話中は処理を行いません。
⑨Stable Diffusion用モデルファイルオープン
⑩Stable Diffusion用Vaeパス
⑪Stable Diffusion用Vaeファイルオープン
⑫Stable Diffusion用Embedding Supportパス
⑬Stable Diffusion用Embedding Supportファイルオープン⑭Llava用システムプロンプト㉓システム設定画面更新ボタン
⑮Llava用コンテキストサイズ
⑯Llava用テンプチャ
⑰Llava用GPUレイヤー数
⑱アンチプロンプト
・Llama3系のLLMが動作しない場合は、「User:」を「User:, <|eot_id|>」に変更してください。
⑲Llava用LLMモデルパス
⑳Llava用LLMモデルファイルオープン
㉑Llava用Clipモデルパス
㉒Llava用Clipモデルファイルオープン
㉔Stable Diffusion生成画像サイズ(CPUなので大きいと時間大)
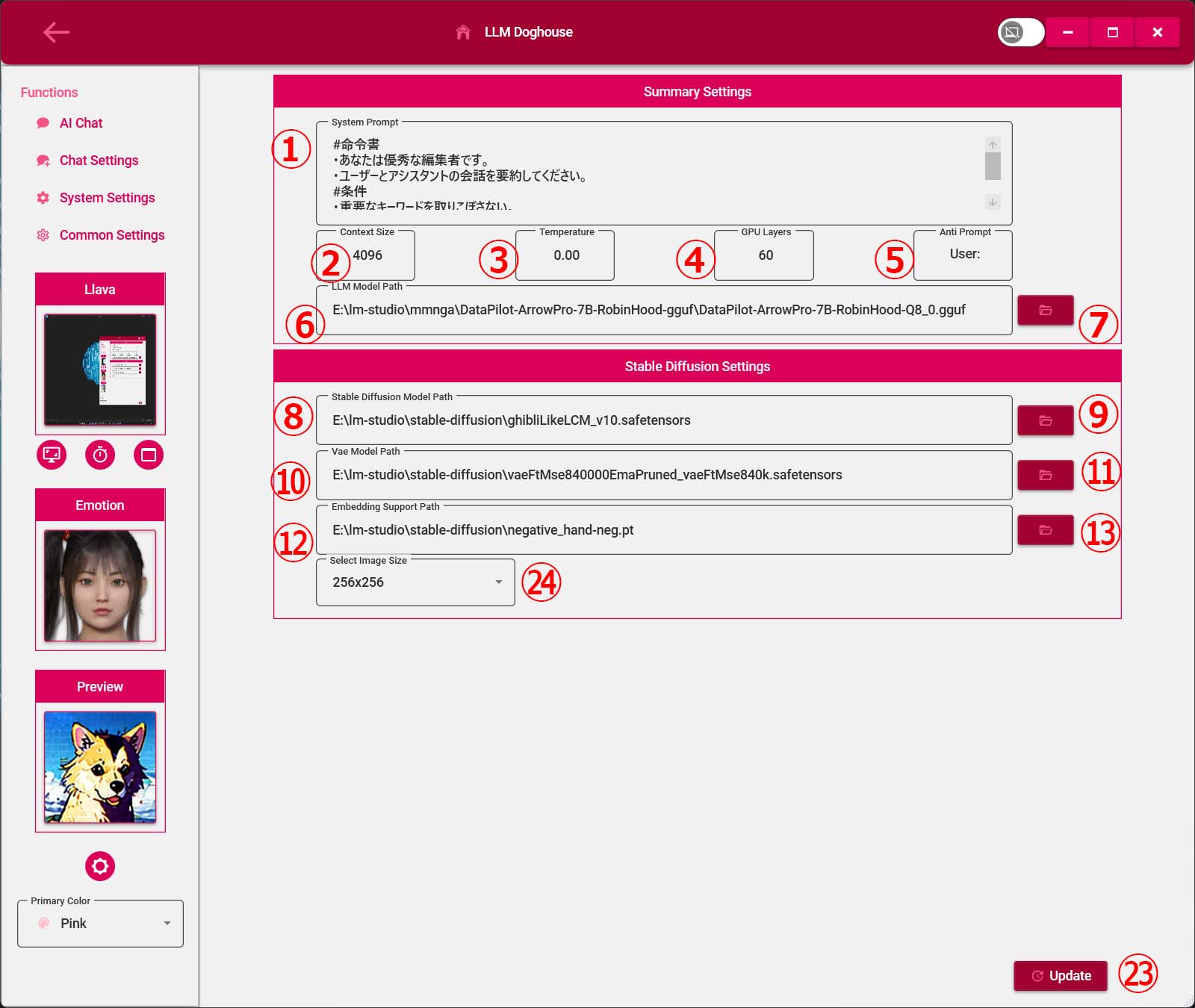
6.共通設定画面
①共通システムプロンプト
・チャットキャラに関係なくシステムプロンプトに挿入する。
②会話、ボイスコマンド、日付ロケール
③ボイスコマンド1活性(マイクオン)
・LLMロード済でマイクオフの時のみ有効
④ボイスコマンド1キーワード
・「,」で複数指定可能。例)マイクオン,おきて,おきなさい
⑤ボイスコマンド2活性(マイクオフ)
・マイクオンの時のみ有効
⑥ボイスコマンド2キーワード
・「,」で複数指定可能。例)マイクオフ,お休み,さようなら
※会話と同じシステムを使用しているため変換後の言葉を指定
⑦ボイスコマンド3活性(アプリ終了)
※マイクオフの時のみ有効
⑧ボイスコマンド3キーワード
・「,」で複数指定可能。例)しゅうりょう,おわり
⑨音声会話タイムアウト活性
・タイムアウトになるとマイクボタンを自動オフ。
⑩音声会話タイムアウト(秒)
⑪AIあいさつ活性化
・音声会話オンになった時にAIから挨拶する。アプリ起動して1回のみ。
⑫AIあいさつキーワード
⑬AIあいさつ指示文
・AIがあいさつするように指示をする内容をシステムプロンプトに挿入する。
⑭AI質問活性化
⑮AI質問キーワード
⑯AI質問指示文
・AIが質問するように指示をする内容をシステムプロンプトに挿入する。
⑰AI質問時間(秒)
・音声会話中に指定した時間以上に沈黙が続いた場合にAIから質問する
⑱禁止用語活性化(Windowsキー+Hで歯車ボタンを押すと不適切フィルター解除ができるらしい)
⑲禁止用語置換文字
・音声会話で禁止用語が使えないため文字にするときに強制的に置き換えする文字を指定する。
例)TK,チンコ,MK,マンコ(カンマで指定する)
チンコと言いたいときはティーケイと話すとよい
⑳共通設定画面更新ボタン㉑会話待ち時間
・ユーザー音声を聞き取る時にAIの音声が入ってしまう場合に待ち時間として秒数を指定する。単一指向性マイクやヘッドセット使用時は、できるだけ短く設定することでスムーズな会話ができる。
7.その他
起動パラメータを指定するとLLMをロードした状態で起動できます。
例)llm_Doghouse.exe /ch1
チャットキャラ1番で起動
ダウンロード
・LLM_Doghouse本体(0.0.2.2) (1.5GB)
※LLM_Doghouse.exeを起動してください。
※最初に.NET8のインストールが始まるかも知れないので逆らわずにインストールしてください。
※前バージョンのチャット履歴を活かしたい場合は、前バージョンChatDB.dbを複写してください。
・LLM_Doghouse本体(0.0.2.2)VULKAN版 (1.3GB)
nvidiaのグラボを搭載していないノートPC(surface pro)でgemma-3-4b-it-Q4_K_S.ggufが動作しました。
※LLM_Doghouse.exeを起動してください。
※最初に.NET8のインストールが始まるかも知れないので逆らわずにインストールしてください。
※前バージョンのチャット履歴を活かしたい場合は、前バージョンChatDB.dbを複写してください。
※nvidiaのグラボのない人またはCUDA Toolkit入れたくない人用。ブルースクリーン出る場合は中止してください。
・LLM Doghouseソース(0.0.2.2)
※Visual Studio 2022 professionalで開発
※エモーション画像(*png)は実行ファイルとおなじフォルダに移動してください。
※Shigobu様作成のVOICEVOX coreのラッパー:VoicevoxCoreNetを使用
※Discord Botの音声送信にはffmpeg.exeとlibsodium.dllが必要です。下記リンクよりDLしてください。
・CUDA ToolKit Dawnload Nowからダウンロード。ユーザー登録は任意なのでxでスキップできる
※VULKAN版のひとは必要ないです。
ソースからEXEを作成する場合は下記をダウンロードして入れてください。
・VOICEVOX core(voicevox_core-windows-x64-cpu-0.15.9で動作確認した) =>Releases · VOICEVOX/voicevox_core
・open_jtalk_dic_utf_8-1.11 =>https://sourceforge.net/projects/open-jtalk/
こんな感じになるようにしてください
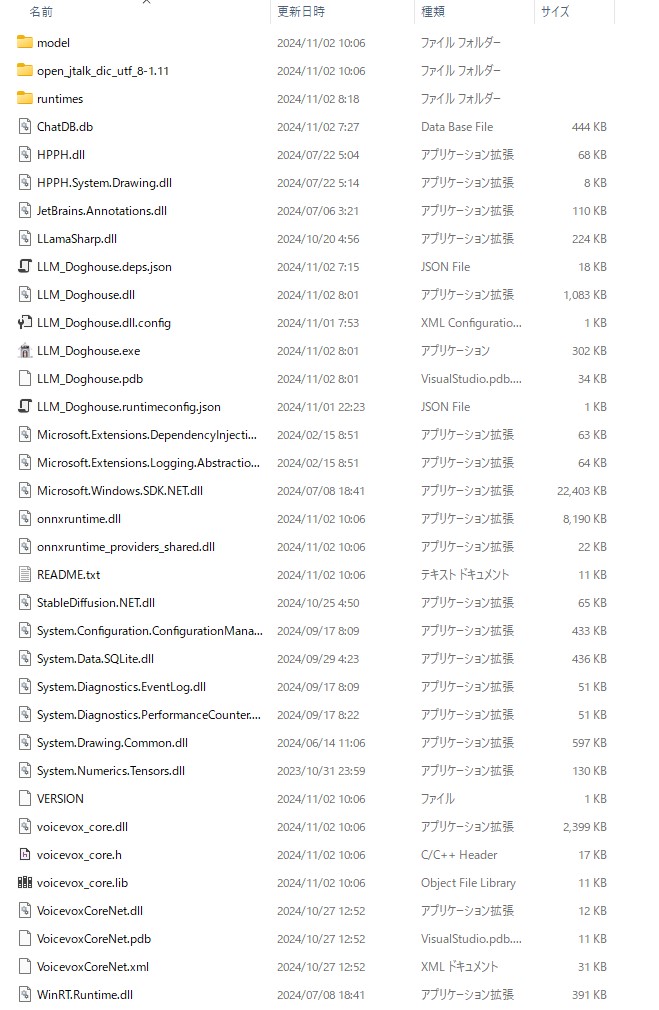
・ffmpeg.exe
オープンソースで開発されているマルチメディアフレームワークで、動画や音声の記録、変換、再生、ストリーミングなどの機能を提供するソフトウェアです。
・libsodium
暗号化、復号化、署名、パスワードハッシュなどのための最新の使いやすいソフトウェアライブラリです。
LLM関連
・DataPilot-ArrowPro-7B-RobinHood-gguf
要約がいい感じの優秀LLM。GPUメモリがあまりないひとはQ4あたりがいいと思う。
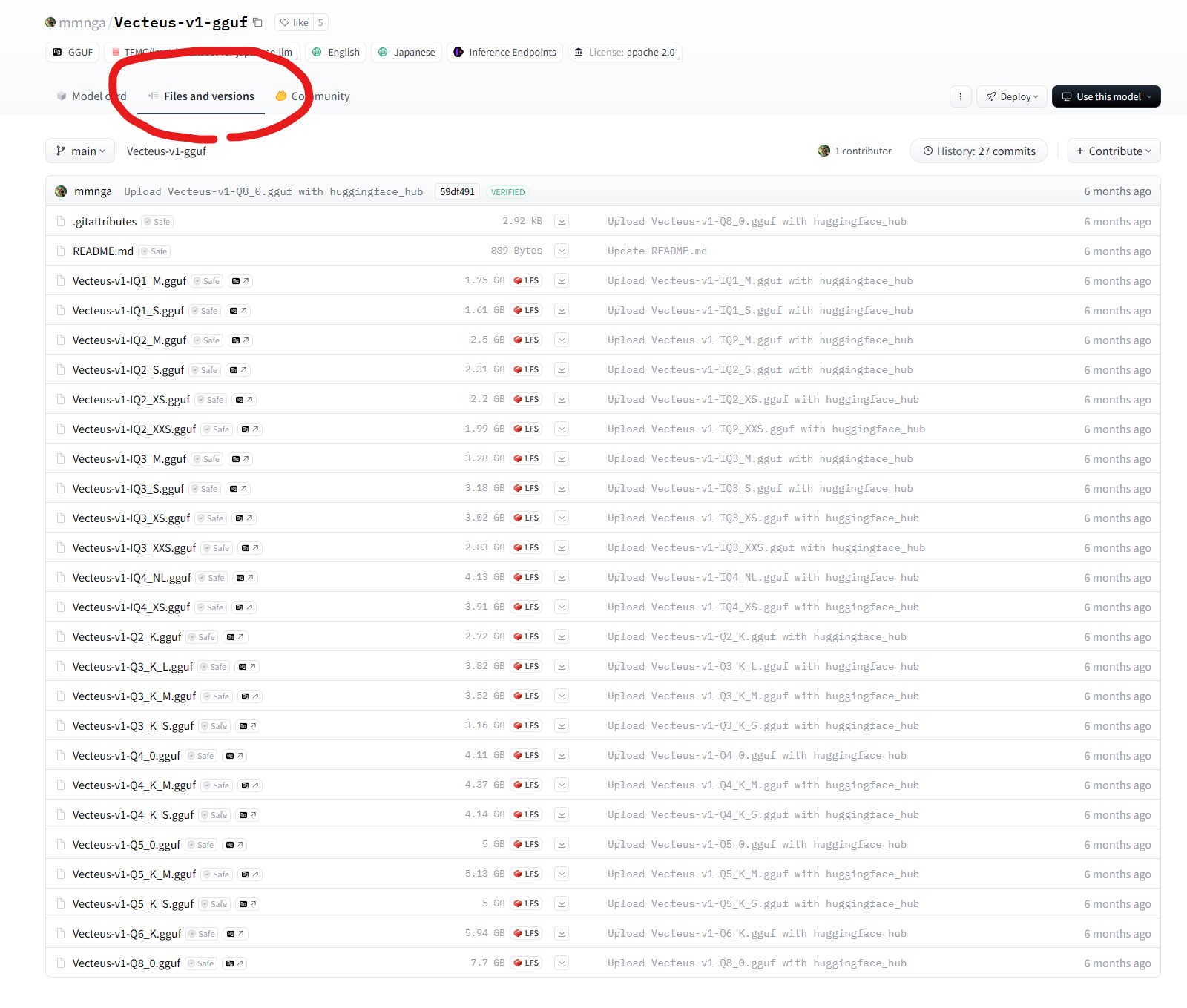
・Vecteus-v1-gguf
Hな会話も可能な優秀LLM。7BなのでGPUメモリが8GB以上でQ8が動く。
GeForce GTX 1650 Max-Q 4GB GDDR5搭載のノートでVecteus-v1-Q4_K_Mが動作。
・Ayla-Light-12B-v3-i1-GGUF
上のAyla-LightのV3モデル。実感としてはV2の方がいいかも?メモリ24GB載ってるなら40000ぐらいまでコンテキストサイズを指定できます。
・gemma-3-12b-it-GGUF
gemma3のimatrix版。LLaveを使う場合はmmproj-BF16.ggufが必要。
GeforceRTX3060 12GBなら動くと思います。
・Aratako.Qwen3-8B-NSFW-JP-GGUF
Aratako氏によるQwen3の日本語+NSFWチューニング版
・ChatWaifu_2.0_vision-GGUF
ChatWaifuのLLaveバージョン。LLaveを使う場合はChatWaifu_2.0_vision.mmproj-Q8_0.ggufが必要。Mistral系だと思う。
・pixtral-12b-GGUF
Mistral系のLLM。LLaveを使う場合はpixtral-12b.mmproj-Q8_0.ggufが必要。
・gemma-3-4b-it-GGUF
vulkan + gemma-3-4b-it-Q4_K_S.ggufでノートPCやRYZEN5600G環境で動きました。ただしひ弱な環境だとLlavaは動かないかも。
・補足:HuggingFaceからダウンロードする場合、下記のタブにファイルがある。
Stable diffusion関連
・モデル:https://civitai.com/models/84728/photon 人物以外も可能
・Vae:sd-vae-ft-mse-original キレイになるらしい
・Emb:negative_hand Negative Embedding 手が変になるのを防ぐらしい
その他ツール
・DB Browser for SQLite SQLiteを操作できるツール。ChatDBの中身が見たい時や履歴をいじりたい時に使ってください。
履歴
| Ver. (リリース日付) | 説明 |
|---|---|
| 0.0.2.2(2025/7/21) | ・会話モードの調整 ・Llavaモードの時にPrefix、Sufixの切り替えにバグを修正 ・VoiceVoxのキャストを最新化 ・2025/12/13 バグがありましたので再アップしました。 ・2025/12/13 フルHD(1980X1080)で実行できるように調整しました。 ・2025/12/27 vulcan版がダウンロードできない不具合を修正しました。 |
| 0.0.2.1(2025/7/3) | ・音声会話モードにすると終了するバグを修正しました。 |
| 0.0.2.0(2025/6/28) | ・Llava機能を本体統合 ・Llavaサブ機能を廃止 ・Llavaで読み込んだ画像をデータベースに記録するようにした。 ・Llavaで読み込みたいウィンドウをHookできるようにした。※一部読み込めない領域あり |
| 0.0.1.13(2025/6/08) | ・音声会話でAIの声を拾ってしまうのを調整しました ・CeVIO AI 弦巻マキが正しく動作しないバグを修正しました ・チャット設定画面のCeVIO AIのコンボボックスでトーカーが重複して表示されるバグを修正しました |
| 0.0.1.12(2025/5/23) | ・LLamaSharp0.24.0対応(Qwen3対応) ・Assistant:、User:の文字を取り除く処理を修正 |
| 0.0.1.11(2025/4/28) | ・チャット画面の履歴行の編集ボタンを追加 ・システム設定にStable Duffusionの画像サイズを設定できるようにした ・初期にDatabaseを作成するときにRowデータが作成されないバグを修正しました |
| 0.0.1.10(2025/4/20) | ・タイトルバーにTopMost(常に前面に)トグルボタンを追加 ・チャット設定画面のNewボタンの横にチャット履歴コピー用トグルボタンを追加 ・チャット画面のピクトにツールチップで説明が出るようにした ・ChatDB.dbが存在しない場合、プログラムから作成できるようにした ・独自で指定したエモート画像が表示されないバグを修正(2025/4/21追加) |
| 0.0.1.9 (2025/3/20) | ・LLamaSharp0.23.0対応(gemma3対応) |
| 0.0.1.8 (2025/3/7) | ・トークン桁数、会話待ち時間の項目を追加 ・会話行をCtrl+Cでクリップボードコピーできるようにした |
| 0.0.1.7 (2025/2/8) | ・Stablediffusionが異常終了するためDownVer.を行った |
| 0.0.1.6 (2025/2/3) | ・LLamaSharp0.21.0対応(DeppSeek対応) |
| 0.0.1.5 (2025/1/29) | ・マイクボタンとスピーカーボタンを分けた ・チャット設定画面にFrequencyPenaltyを追加 ・LLamaSharp0.20.0対応 |
| 0.0.1.4 (2024/12/20) | ・ウィンドウ上部の白い部分の削除 ・アプリ内の定数を変更できるようした ・音声会話が切れてしまうバグ修正 |
| 0.0.1.3 (2024/12/7) | ・履歴行の削除ボタンを追加 ・Discordで音声会話を開始するとBotが文字と音声を返すようにした ・Primery ColorをPrimary Colorに修正 ・ピクトの表示がされないバグを修正 |
| 0.0.1.2 (2024/11/30) | ・プライマリーカラー選択機能 ・メッセージボックスをMaterial Design対応 ・ウィンドウ位置サイズ、ダーク/ライトモードが保存できないバグを修正 ・システムプロンプト項目で設定していた先頭にAssistant:をつけるという文言をアプリ側に移動した、この文言がないとエーエスエス・・・とかを読み上げてしまう |
| 0.0.1.1 (2024/11/24) | UI(ユーザインターフェース)を見直し |
| 0.0.0.6 (2024/11/9) | エモート画像表示機能を追加 |
| 0.0.0.5 (2024/11/7) | 設定が1件もない状態でEditダイアログを開いたときCevioAI、VOICEVOXのドロップダウンリストが空になるバグを修正。Editダイアログにチャット履歴削除ボタンを追加。 |
| 0.0.0.4 (2024/11/7) | VOICEVOX coreの初期化エラー対応、SpeechRecognizerが止まってしまうバグを修正、タイマー処理調整 |
| 0.0.0.3 (2024/11/6) | Discord Bot機能追加、Editボタンで戻ってきたときにドロップダウンリストが最初に戻るバグを修正 |
| 0.0.0.2 (2024/11/4) | EditでSynthesis、CevioAI、VOICEVOXが反映さればいバグを修正、Llvaα機能追加 |
| 0.0.0.1 (2024/11/2) | 初期リリース版 |