LlavaでローカルLLMに画像認識させるc#プログラム
少し横道に逸れますがLlavaを使ってLLMに画像認識させて説明をしてもらうc#プログラムです。
ほぼExampleのままです。
LLMモデル以外にVision Adapterが必要になります。LM Studioで「llava」で検索してダウンロードできます。
赤枠がVision Adapterです。LLMモデルは下の方のQ8をダウンロードしてください。
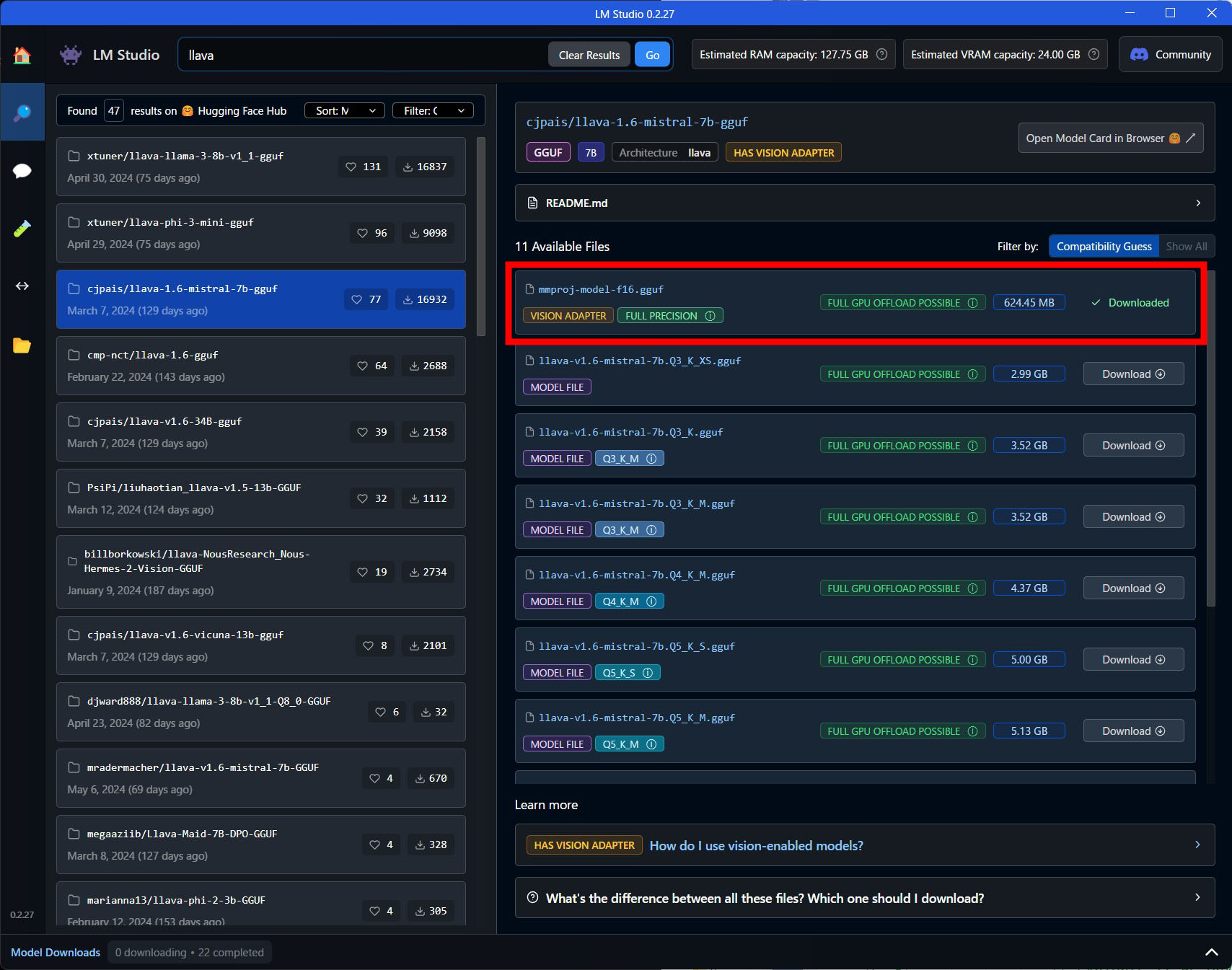
コンソールに画像表示するためにSpectre.ConsoleをNuGetしています。

下記がコードです。1個目の画像をmodelImageで指定しています。
2個めからはチャットで「{c:\image\test02.jpg}の画像の詳細な説明を入力してください。」というような形で入力してください。
using System.Text.RegularExpressions;
using LLama.Common;
using Spectre.Console;
using LLama.Native;
namespace LLama.Examples.Examples
{
// この例では、画像とテキストの両方を入力として LLaVA モデルとチャットする方法を示します。
// 推論には対話型エグゼキュータを使用します。
public class LlavaInteractiveModeExecute
{
static void Main(string[] args)
{
//コンソールアプリケーションからAsyncを呼び出す大元はTaskを使用する
Task task = MainAsync();
//終了を待つ
task.Wait();
}
public static async Task MainAsync()
{
string strModelPath = Environment.GetEnvironmentVariable("LLMPATH", System.EnvironmentVariableTarget.User) + @"cjpais\llava-1.6-mistral-7b-gguf\llava-1.6-mistral-7b.Q8_0.gguf";
string strMmPrjPath = Environment.GetEnvironmentVariable("LLMPATH", System.EnvironmentVariableTarget.User) + @"cjpais\llava-1.6-mistral-7b-gguf\mmproj-model-f16.gguf";
string multiModalProj = strMmPrjPath;
string modelPath = strModelPath;
string modelImage = @"E:\image\test01.jpg";
const int maxTokens = 512;
var prompt = $"{{{modelImage}}}\nUSER:\n画像の詳細な説明を入力してください。\nASSISTANT:\n";
var parameters = new ModelParams(modelPath);
using var model = LLamaWeights.LoadFromFile(parameters);
using var context = model.CreateContext(parameters);
// Llava Init
using var clipModel = LLavaWeights.LoadFromFile(multiModalProj);
var ex = new InteractiveExecutor(context, clipModel);
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("実行プログラムが有効になりました。この例では、プロンプトが出力され、最大トークンは {0} に設定され、コンテキスト サイズは {1} です。", maxTokens, parameters.ContextSize);
Console.WriteLine("画像を送信するには、{c:/image.jpg} のように、ファイル名を中括弧で囲んで入力します。");
var inferenceParams = new InferenceParams() { Temperature = 0.1f, AntiPrompts = new List<string> { "\nUSER:" }, MaxTokens = maxTokens };
do
{
// Evaluate if we have images
//
var imageMatches = Regex.Matches(prompt, "{([^}]*)}").Select(m => m.Value);
var imageCount = imageMatches.Count();
var hasImages = imageCount > 0;
if (hasImages)
{
var imagePathsWithCurlyBraces = Regex.Matches(prompt, "{([^}]*)}").Select(m => m.Value);
var imagePaths = Regex.Matches(prompt, "{([^}]*)}").Select(m => m.Groups[1].Value).ToList();
List<byte[]> imageBytes;
try
{
imageBytes = imagePaths.Select(File.ReadAllBytes).ToList();
}
catch (IOException exception)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.Write(
$"Could not load your {(imageCount == 1 ? "image" : "images")}:");
Console.Write($"{exception.Message}");
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("Please try again.");
break;
}
// 画像が表示されるたびにキャッシュをクリアします
// プロンプトに画像が含まれている場合は、KV_CACHEをクリアして会話を再開します。
// See:
// https://github.com/ggerganov/llama.cpp/discussions/3620
ex.Context.NativeHandle.KvCacheRemove(LLamaSeqId.Zero, -1, -1);
int index = 0;
foreach (var path in imagePathsWithCurlyBraces)
{
// 最初の画像をタグ<image>に置き換え、残りの画像ではタグを削除します。
prompt = prompt.Replace(path, index++ == 0 ? "<image>" : "");
}
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine($"Here are the images, that are sent to the chat model in addition to your message.");
Console.WriteLine();
foreach (var consoleImage in imageBytes?.Select(bytes => new CanvasImage(bytes)))
{
consoleImage.MaxWidth = 50;
AnsiConsole.Write(consoleImage);
}
Console.WriteLine();
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine($"画像はコンソール用に縮小されており、モデルはフルバージョンになります。");
Console.WriteLine($"終了するには、exit と入力するか、Ctrl+c を押します。");
Console.WriteLine();
// Initialize Images in executor
//
foreach (var image in imagePaths)
{
ex.Images.Add(await File.ReadAllBytesAsync(image));
}
}
Console.ForegroundColor = ConsoleColor.White;
await foreach (var text in ex.InferAsync(prompt, inferenceParams))
{
Console.Write(text);
}
Console.Write(" ");
Console.ForegroundColor = ConsoleColor.Green;
prompt = Console.ReadLine();
Console.WriteLine();
// let the user finish with exit
//
if (prompt != null && prompt.Equals("exit", StringComparison.OrdinalIgnoreCase))
break;
}
while (true);
}
}
}
実行結果です
1.読み込んだ画像

コンソール画像はモザイクっぽくなっていますがLLMには上の画像が渡せています。
結果
「この画像には、一匹の灰色猫が含まれています。猫は、ピンクカラフで敷されたものに座っています。猫は、黄金色の目を持ち、その周りには、眉や鼻があります。猫は、左側 から右側へと、左腕から右腕へと前 前にも、歩いたような立ち です。背景は、ピンクカラフの中央にあるものを含むことができません。」
ちゃんと画像が猫だとわかっているようですね。

2.読み込んだ画像

結果
「この画像は、人間のような形状を持つ団体です。その中には、色や形状が異なるものがあります。例えば、一部分は、青い色として描かれており、他の部分は、赤い色として描かれています。また、団体内には、三角形や四角形な どの形状があります。この画像は、人間のような形状を持つ団体であることがわかります。」
うしろのモコモコとの判別が難しいようです。生物だと認識はしてるようです。

LLMと会話するときに、表情を読み取れるのかテストしましたが表情から機嫌を読み取ることはできないと返されました。
もう少し時間が必要ですね。
