簡単なWebページをスクレイピングするc#プログラム
前回は、KernelMemoryに食わすURLアドレスを求める巡回プログラムをやりましたが、いざLLMにWebアドレスを渡しても全然認識できませんでした。マイ曰く「わかるわけないじゃん」だそうです。スクレイピングしてあげないと勝手に見てねは通用しないのではないかと思います・・・たぶん(自信ない)
ということでHtml Agility packを使ったスクレイピングの簡単なプログラムを掲載します。
Nuget情報

概要
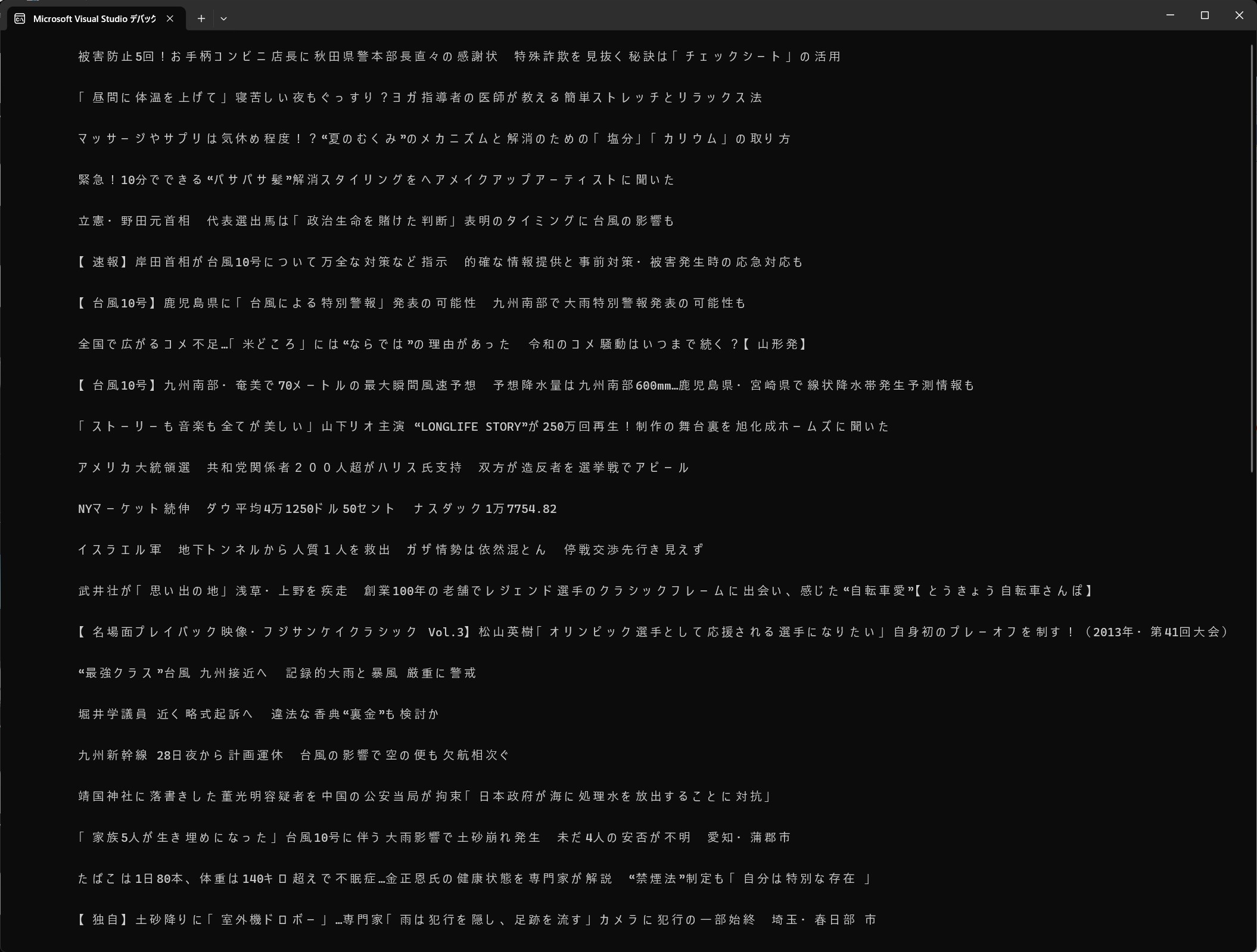
FNNニュースサイトにアクセスしてhtml情報を取得しトピックが書かれているタグを見てスクレイピングする。ほんとはHtml Agility packに直接URLを渡したかったのですが、なぜか内部のディレクトリを見に行ってエラーになるので仕方なくWebClientを通しています。
↑使い方が間違っていました。new HtmlWebで正解。
using HtmlAgilityPack;
class Program
{
static void Main()
{
// Load HTML document from a file or URL
HtmlWeb web = new HtmlWeb();
var htmlDocument = web.Load("https://www.fnn.jp/");
// Select nodes using XPath
var nodes = htmlDocument.DocumentNode.SelectNodes("//h2[@class='m-article-item-info__ttl']");
// Extract and display data
foreach (var node in nodes)
{
Console.WriteLine(node.InnerHtml);
}
}
}
とはいうものの、上記は文字化けするのでWebClientを使った方が正解のようです^^;
using HtmlAgilityPack;
using System.Net;
class Program
{
static void Main()
{
// Load HTML document from a file or URL
WebClient webClient = new WebClient();
string page = webClient.DownloadString("https://www.fnn.jp/");
var htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(page);
// Select nodes using XPath
var nodes = htmlDocument.DocumentNode.SelectNodes("//h2[@class='m-article-item-info__ttl']");
// Extract and display data
foreach (var node in nodes)
{
Console.WriteLine(node.InnerHtml);
}
}
}
結果
これならマイもわかってくれるだろう。
固有のタグ調べてスクレイピングせんならんやったら巡回で無作為にアドレス持って来れんやんなあ・・・